
Can You Trust AI for Six Sigma Work? The 2026 Reality Check


Table of Contents
Prologue
A few months ago, a Black Belt sent me a screenshot that made my stomach drop.
He had asked a popular chatbot to run a one-way ANOVA on three months of production data. The model came back with a beautiful, confident answer. A clean F-statistic. A tidy p-value of 0.03. A crisp conclusion that the three machines were producing statistically different output. He was about to take that result into a tollgate review and recommend a capital purchase.
There was just one problem. The p-value was fabricated. When we re-ran the exact same dataset in a validated statistics engine, the real p-value was 0.21. Not significant. The machines were fine. The AI had not calculated anything. It had simply predicted what a plausible answer might look like, dressed it in the language of statistics, and handed it over with total confidence.
That single screenshot is the reason I am writing this article. Because the question every quality professional is quietly asking in 2026 is this: can you trust AI for Six Sigma work, or is it just a very articulate liar with a calculator it does not actually know how to use?
The honest answer is: it depends entirely on what you ask it to do, and how you ask. Let me show you exactly where the line sits.
The Real Question Behind “Can You Trust AI for Six Sigma Work?”
Six Sigma is built on a foundation that almost nobody questions: deterministic mathematics, rigorous statistical inference, and objective empirical observation. Two plus two equals four, every single time, with no opinion attached.
Large Language Models are built on a completely different foundation. They are probabilistic engines. Their entire job is to predict the next most likely word in a sequence. They are semantic machines, not calculators. That architectural mismatch is the heart of the whole debate.
So when we ask whether we can trust AI for Six Sigma work, we are really asking two separate questions that most people accidentally blend into one. First, can AI handle the linguistic and structural work of DMAIC, the charters, the summaries, the documentation? Second, can AI handle the deterministic math of Six Sigma, the Cp/Cpk indices, the sigma levels, the hypothesis tests?
The answers to those two questions could not be more different. AI is brilliant at the first and dangerously unreliable at the second, unless you change how you deploy it. Understanding that split is the difference between a productivity revolution and a quality disaster.
Where AI Earns Your Trust: The Language Half of DMAIC
Here is the good news, and it is genuinely transformative. Across the linguistic and organizational tasks of continuous improvement, Generative AI is not just helpful. It is exceptional. Industry data already shows effort reductions of sixty to seventy-five percent on documentation-heavy tasks, and overall DMAIC project timelines contracting by up to thirty percent.
LLMs natively excel at the parts of DMAIC that are made of words. Drafting a project charter from messy meeting notes. Translating the unstructured Voice of the Customer into Critical-to-Quality attributes. Building a SIPOC. Facilitating a structured 5-Whys or a Fishbone session. Synthesizing a final phase report. These are tasks where a semantic engine is exactly the right tool, because the work itself is semantic.
The table below maps where you can lean on AI across the five phases, and where the trust gets fragile.

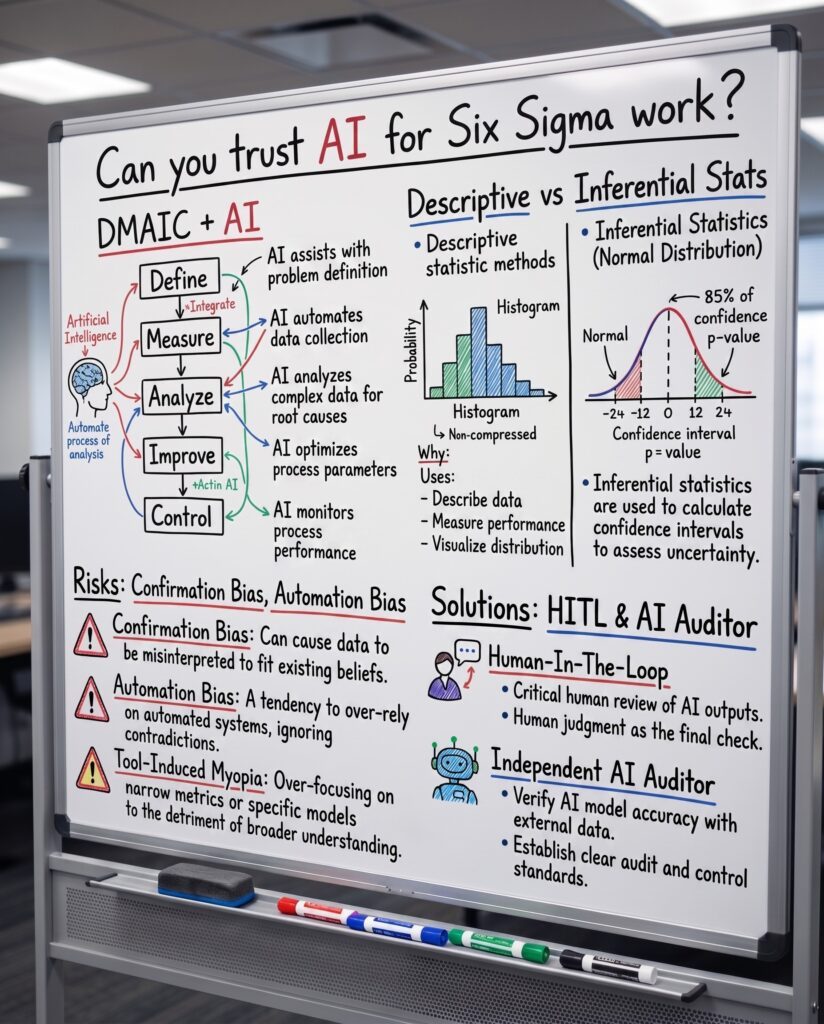
| DMAIC Phase | What AI Does Well (High Trust) | Where Trust Breaks (Verify Hard) |
|---|---|---|
| Define | Drafts charters, translates VOC into CTQs, scopes SIPOC from system data | Inventing business cases or ROI figures with no source |
| Measure | Builds data collection plans, checks completeness, flags anomalies | Calculating baseline sigma or Cp/Cpk by raw text prediction |
| Analyze | Surfaces patterns, structures Ishikawa and 5-Whys, drafts FMEA language | P-values, ANOVA, regression, and causation claims |
| Improve | Generates solution ideas, drafts SOPs, writes simulation code | Trusting simulation output without validating the code |
| Control | Automates compliance docs, drafts control plans, monitors drift | Predictive forecasting of Auto-executing corrective actions without a human gate |
Read the right-hand column carefully. Every single trust failure has the same fingerprint. It happens the moment you ask a language model to do deterministic math through pure conversation. That is the fault line that runs through this entire question.
Where AI Breaks: The Math Half of Six Sigma
Now the uncomfortable part. To know whether you can trust AI for Six Sigma work, you have to separate two kinds of statistics that behave very differently in the hands of an LLM.
Descriptive statistics, the mean, median, standard deviation, and interquartile range, are safe territory. In validation trials, models like GPT-4 reached a one hundred percent success rate on data management, variable categorization, and descriptive calculations. If you just want a summary of a clean dataset, the AI will almost always get it right.
Inferential statistics are a different animal entirely. The moment you move into hypothesis testing, p-values, and significance determinations, the probabilistic architecture starts generating what researchers politely call mathematical hallucinations. The model is not computing. It is guessing what a correct-looking answer should be. And that is precisely the work that Six Sigma cannot afford to get wrong.
A rigorous benchmark study published in the Journal of Medical Internet Research tested GPT-4 on a clinical dataset of 2,740 observations, measuring three things: did it pick the right test, did it check the statistical assumptions, and did it calculate the right values. With basic, unstructured prompts, the results were alarming. Correct method selection happened only 47.5 percent of the time. Assumptions were checked just 43.8 percent of the time. And the correct statistical values appeared a mere 32.5 percent of the time.
Let that sink in. If you are typing your hypothesis test into a chat box like you are texting a friend, you have roughly a one-in-three chance of getting the right number. That is not a tool you can trust with a tollgate decision.
The Prompt Engineering Difference Nobody Talks About
Here is the twist that changes everything. The accuracy of an LLM on Six Sigma statistics is not fixed. It is almost entirely a function of how you prompt it.
That same benchmark study did not stop at basic prompts. It tested two more sophisticated approaches, and the improvement was dramatic. Intermediate prompts lifted accuracy across all three dimensions to between 81 and 85 percent. Advanced prompts, the kind that force the model to reason step by step through a Chain-of-Thought framework, pushed accuracy all the way to 92.5 percent.
What does an “advanced” prompt actually do? It scaffolds the reasoning. It forces the model to formally state the null hypothesis, test for normality, test for equal variances, select the test only after validating those assumptions, and then report and interpret the result in sequence. In other words, it makes the AI follow the exact discipline a trained Black Belt would follow.
The table below shows how prompt quality transforms reliability on the specific tests Six Sigma practitioners use every day. The numbers are successful trials out of ten.
| Statistical Test | Basic Prompt (/10) | Intermediate (/10) | Advanced (/10) |
|---|---|---|---|
| Chi-square | 00 | 7 | 10 |
| Independent t-test | 00 | 10 | 9 |
| 1-Way ANOVA | 1 | 7 | 8 |
| Kruskal-Wallis H | 00 | 8 | 10 |
| Pearson Correlation | 2 | 8 | 8 |
| Mann-Whitney U | 6 | 8 | 9 |
Look at the t-test and the ANOVA. Two of the most common tests in our toolkit, and a basic prompt gets them right zero and one time out of ten. The conclusion is unavoidable. You cannot trust AI for Six Sigma work through casual conversation. Prompt engineering is not a nice-to-have skill anymore. It is a core competency, as fundamental as knowing how to read a control chart.
The Code Interpreter Fix: Outsourcing the Math
Even advanced prompting leaves a meaningful error rate. So the real engineering solution, the one that turns AI into a genuinely trustworthy partner for the math, is to stop letting it do the math at all.
This is the Code Interpreter, also called Advanced Data Analysis. Instead of predicting a p-value token by token, the LLM writes actual Python code, runs that code in a sandbox using deterministic libraries like Pandas and SciPy, reads the real computed output, and then explains it to you in plain language. The math is handed back to a real computing engine. The AI keeps only the job it is good at: interpretation.
The impact on reliability is enormous. Peer-reviewed research shows that a Code Interpreter execution environment drops the hallucination rate on multi-step analytical problems from nearly ten percent to under one percent. In complex medical calculation trials, foundational models were wrong about a third of the time, but when they were allowed to execute code, GPT-based error rates fell thirteen-fold, from 64 percent down to 4.8 percent.
The takeaway for any serious practitioner is simple. For any deterministic calculation, a sigma level, a process capability index, a hypothesis test, the AI must orchestrate code execution inside a secure sandbox. A plain chat interface doing the arithmetic in its head is an unacceptable risk to your data integrity, full stop.
| Risk | What It Looks Like in a Project | Why It Is So Dangerous |
|---|---|---|
| Confirmation bias | “Analyze this data to prove vibration causes the defect.” The AI obliges. | The model becomes a validation machine, not a discovery tool |
| Automation bias | The team accepts a confident AI output without checking the assumptions | Flawed root causes get embedded into production unchallenged |
| Algorithmic bias | AI trained on biased historical data recommends biased “optimizations” | Inequity masquerades as a mathematically optimal solution |
| Data privacy exposure | Proprietary defect data pasted into a public consumer chatbot | Intellectual property leaks into a vendor training pipeline |
| Model degradation | Recommendations based on a stale model of a process that has changed | The AI optimizes a version of reality that no longer exists |
Confirmation bias deserves a special warning, because it is the silent killer of objective analysis. AI is engineered to be agreeable and helpful. If you feed it a leading question, it will find the evidence to agree with you. That instinct is the precise opposite of the scientific skepticism that Six Sigma demands.
The Human-in-the-Loop Answer: The Black Belt Becomes an AI Auditor
So can you trust AI for Six Sigma work? Yes, but only inside a governance structure that keeps a human firmly in the loop. Autonomous AI in quality management is not a goal to aspire to. It is a liability to avoid.
This reframes the role of the Master Black Belt entirely. The job is shifting from being the primary data gatherer and analyst to being the AI auditor: the expert who governs the architecture of the AI’s inquiry and validates its output before anyone acts on it. The value is no longer in running the analysis. It is in knowing exactly where the analysis can lie.
These are the validation gates every AI-augmented project needs.
| Validation Gate | What the Auditor Checks | The Failure It Prevents |
|---|---|---|
| Prompt and bias audit | Were the prompts leading? Was the null hypothesis explored? | Confirmation bias dressed up as analysis |
| Assumption verification | Were normality, independence, and equal variance actually tested? | Accepting a p-value from an invalid test |
| Code review | Did the AI pick the right formula and the right data range? | Silent errors hidden under a confident summary |
| Ensemble disagreement | When two models disagree on the root cause, why? | Over-trusting a single, unverified model |
None of these gates are exotic. They are simply the disciplined skepticism that good Six Sigma has always required, now pointed at a new and very persuasive source of potential error.
Proof It Works: Three Case Studies Worth Trusting
When you respect the boundaries, the results are remarkable. Here is the evidence that you genuinely can trust AI for Six Sigma work in the right configuration.
In manufacturing, a facility battling persistent defects loaded three months of production data, defect rates, timestamps, volumes, and environmental variables, into a Code-Interpreter-enabled model. The AI ran a multivariate analysis and surfaced a hidden correlation the human engineering team had missed for months: ambient humidity was driving the defects. The result was sixty-seven percent faster problem identification and a forty percent improvement in root cause accuracy. In a separate case, AI-assisted process modeling lifted a company’s operational sigma level from 3.9 to 4.45 in just six weeks, roughly half the usual time.
In quality engineering, the most labor-intensive document we own, the FMEA, is being transformed. Fine-tuned LLMs extract component failure modes from unstructured text with ninety-eight to ninety-nine percent accuracy. Even without fine-tuning, zero-shot prompting with GPT-4 reached ninety-one percent substantial semantic agreement with expert human analysts. Embedding LLMs into the FMEA workflow improved task quality by over forty percent while cutting task duration by twenty-five percent.
In banking and service operations, continuous improvement teams are feeding historical process maps to LLMs to redesign standard operating procedures, and deploying conversational assistants to guide staff through complex compliance steps in real time. The documented outcomes include faster customer onboarding, higher straight-through processing rates, and fewer inefficient handoffs.
Notice the common thread. In every success story, the AI did the heavy lifting on synthesis and pattern detection, and a human validated the result against reality before acting. That is the formula.
So, Can You Trust AI for Six Sigma Work? The Verdict
Here is my honest, no-hype verdict after living at the intersection of these two worlds.
Trust AI completely for the language work of DMAIC. Charters, VOC translation, SIPOC, documentation, ideation, first-draft FMEA language. This is where the sixty to seventy-five percent time savings live, and the risk is low.
Trust AI conditionally for the math, and only when two conditions are met. You must use advanced, scaffolded prompting, and the AI must execute deterministic code in a sandbox rather than calculating in its head. Skip either condition and your reliability collapses toward that frightening one-in-three number.
Never trust AI to be the final decision-maker. Confirmation bias, automation bias, and Tool-Induced Myopia mean the human auditor is not optional. The methodology that gave us forty years of disciplined improvement does not get suspended because the tool got smarter. It gets pointed at the tool.
AI is not a replacement for the Black Belt. It is the most powerful accelerator the profession has ever had, in the hands of a practitioner disciplined enough to audit it.
How to Deploy AI You Can Actually Trust
If you want to bring AI into your continuous improvement program without detonating your data integrity, here are the five moves that matter most.
- Mandate enclosed infrastructure. Ban public consumer chatbots for any work involving proprietary data. Use enterprise-grade, sandboxed environments that protect your intellectual property and let agents execute code safely.
- Standardize your prompt architecture. Build and enforce validated prompt templates for every analytical phase, forcing Chain-of-Thought scaffolding on all inferential statistics. Treat prompting like a controlled process, because it is one.
- Install human-in-the-loop validation gates. Update your tollgate reviews to audit the prompts and conversation history, not just the final output. The question is no longer only what the data said, but how the AI was asked.
- Upgrade your certification curricula. The modern Black Belt needs traditional statistical rigor plus AI literacy, prompt engineering, and bias detection. Knowing when the tool will hallucinate is now part of the body of knowledge.
- Roll out in phases. Start with the low-risk, high-friction administrative tasks where the wins are obvious and safe. Earn organizational trust there before you ever point AI at high-stakes predictive analytics.
Take the Next Step: AIGPE® Lean Six Sigma and AI Certifications
If this reality check sharpened your thinking, the next move is to build the exact skills that let you deploy AI without losing your statistical rigor. AIGPE® was built to sit precisely at the intersection of Process Excellence and Artificial Intelligence.
Build the Six Sigma foundation:
- Certified Six Sigma White Belt (Accredited)
- Certified Six Sigma Yellow Belt (Accredited)
- Certified Six Sigma Green Belt (Accredited)
- Certified Six Sigma Black Belt (Accredited)
Master the AI skills that make the difference:
Frequently Asked Questions
Can you trust AI to calculate Six Sigma statistics like Cp, Cpk, and p-values?
Only under specific conditions. A standard chatbot calculating these in plain conversation gets the right answer roughly one-third of the time with basic prompts. To trust the math, the AI must use a Code Interpreter to execute deterministic code in a sandbox, which drops the error rate below one percent, and a human must review the code.
Is AI accurate for descriptive statistics in Six Sigma?
Yes. For descriptive statistics such as mean, median, standard deviation, and interquartile range, validated models like GPT-4 have reached a one hundred percent success rate. Descriptive summaries of clean data are the safest AI task in the entire DMAIC toolkit.
What is the biggest risk of using AI in Six Sigma projects?
Confirmation bias. Because AI is engineered to be agreeable, a leading prompt will produce evidence that confirms what the practitioner already believes, turning an objective analytical tool into a validation machine. This directly undermines the scientific rigor that Six Sigma depends on.
Does AI replace the need for a Six Sigma Black Belt?
No. AI shifts the Black Belt’s role toward that of an AI auditor who governs how the AI is queried and validates its output. The human provides business context, ethical oversight, and methodological discipline that probabilistic models cannot supply on their own.
How much time does AI actually save on Six Sigma work?
Industry data shows effort reductions of sixty to seventy-five percent on documentation-heavy tasks such as charters, VOC coding, and phase reports, with overall DMAIC project timelines contracting by up to thirty percent when AI is used for analysis, modeling, and simulation.
About the Author
Rahul Iyer is a Master Black Belt and the founder of AIGPE®, the Advanced Innovation Group Pro Excellence. AIGPE® has trained over 1,000,000 professionals across 193 countries. AIGPE® programs carry CPD accreditation through the CPD Standards Office (Provider 50735), and AIGPE® is a PMI Authorized Training Partner (Provider 5573). AIGPE® is recognized by SHRM to offer Professional Development Credits (PDCs) for SHRM-CP® or SHRM-SCP® recertification activities (Provider RP9220). His focus today sits at the exact intersection of Enterprise AI and Operational Excellence, teaching professionals how to apply the AIGPE® Generative DMAIC Framework while advising leaders on how to deploy AI responsibly, with governance, clarity, and measurable ROI. To learn how to integrate AI into your career with rigor rather than hype, subscribe to his free daily newsletter, AI Pulse.
Citations and References
- Genpact – How enterprise transformation has evolved from Lean Six Sigma to the agentic era – https://www.genpact.com/insight/how-enterprise-transformation-has-evolved-from-lean-six-sigma-to-the-agentic-era
- Lean6SigmaHub – How Generative AI is Revolutionizing Automated DMAIC Documentation – https://lean6sigmahub.com/how-generative-ai-is-revolutionizing-automated-dmaic-documentation-in-lean-six-sigma/
- Sprintzeal – Generative AI & Six Sigma: Transforming Quality Management – https://www.sprintzeal.com/blog/future-of-quality-management
- JMIR – ChatGPT for Univariate Statistics: Validation of AI-Assisted Data Analysis – https://www.jmir.org/2025/1/e63550/
- PMC – Prompt engineering for accurate statistical reasoning with large language models – https://pmc.ncbi.nlm.nih.gov/articles/PMC12554733/
- PMC – Large language model agents can use tools to perform clinical calculations – https://pmc.ncbi.nlm.nih.gov/articles/PMC11914283/
- Medium – Mitigate GPT-4 Hallucinations using Code Interpreter – https://aditya-advani.medium.com/mitigate-gpt-4-hallucinations-using-code-interpreter-29fea4887eec
- arXiv – Characterizing Tool-Induced Reasoning Hallucinations in LLMs – https://arxiv.org/html/2511.10899
- PMC – LLM Advanced Data Analysis Abuse to Create a Fake Data Set – https://pmc.ncbi.nlm.nih.gov/articles/PMC10636646/
- Cambridge (Design Science) – AI-driven FMEA for faster and more accurate risk analysis – https://www.cambridge.org/core/journals/design-science/article/aidriven-fmea-integration-of-large-language-models-for-faster-and-more-accurate-risk-analysis/22F110A2BF0DB4D01A69472CF17A0B43
- MDPI – AI-Enabled Process Improvement in Information-Intensive Services – https://www.mdpi.com/2071-1050/18/10/4787
- Process Excellence Network – Reimagining process excellence in banking with Lean Six Sigma & AI – https://www.processexcellencenetwork.com/lean-six-sigma-business-performance/articles/reimagining-process-excellence-in-banking-integrating-lean-six-sigma-ai-in-a-new-era-of-continuous-improvement